
Background
Proses pengerjaan machine learning pada umumnya meliputi uji coba berbagai model terhadap dataset dengan memilih model dengan performa terbaik. Untuk mendapatkan hasil prediksi data yang akurat, diperlukan tidak hanya model machine learning yang tepat, tetapi juga hyperparameter (parameter yang mengatur proses pembelajaran mesin) yang tepat pula yang dikenal dengan istilah hyperparameter tuning. Menentukan kombinasi yang tepat antara model dan hyperparameter seringkali menjadi tantangan.
Grid Search Cross Validation adalah metode pemilihan kombinasi model dan hyperparameter dengan cara menguji coba satu persatu kombinasi dan melakukan validasi untuk setiap kombinasi. Tujuannya adalah menentukan kombinasi yang menghasilkan performa model terbaik yang dapat dipilih untuk dijadikan model untuk prediksi.
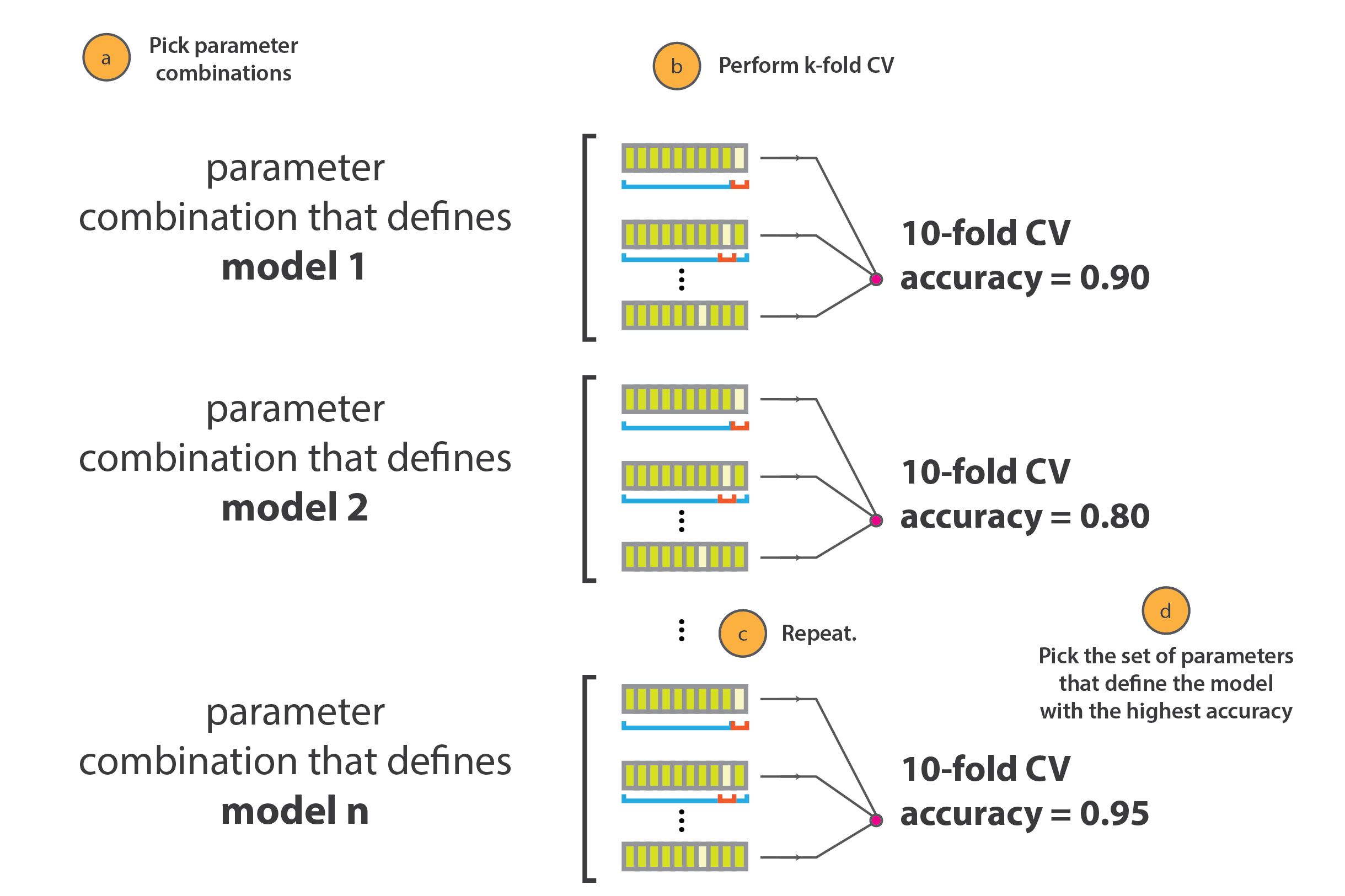
Artikel ini akan membahas bagaimana cara mengoptimasi model machine learning dengan menggunakan metoda Grid Search Cross Validation. Dengan adanya Grid Search Cross Validation, proses pemilihan model dan hyperparameter tuning menjadi lebih mudah. Grid Search Cross Validation melakukan validasi untuk setiap kombinasi model dan hyperparameter secara otomatis sehingga dapat menghemat waktu proses pengerjaan.
Import Library
Import library umum yang digunakan dalam pengolahan data.
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as snsData Understanding
Data yang digunakan pada artikel ini adalah data Vehicle yang diperoleh dari kaggle . Model machine learning pada kasus ini dirancang untuk memprediksi harga mobil bekas berdasarkan kondisi kendaraan saat dijual.
df = pd.read_csv('data_input/Car_details_v3.csv')df.head()#> name year ... torque seats
#> 0 Maruti Swift Dzire VDI 2014 ... 190Nm@ 2000rpm 5.0
#> 1 Skoda Rapid 1.5 TDI Ambition 2014 ... 250Nm@ 1500-2500rpm 5.0
#> 2 Honda City 2017-2020 EXi 2006 ... 12.7@ 2,700(kgm@ rpm) 5.0
#> 3 Hyundai i20 Sportz Diesel 2010 ... 22.4 kgm at 1750-2750rpm 5.0
#> 4 Maruti Swift VXI BSIII 2007 ... 11.5@ 4,500(kgm@ rpm) 5.0
#>
#> [5 rows x 13 columns]df.shape#> (8128, 13)Data ini terdiri dari 8128 baris dengan 13 kolom. Kolom selling_price akan menjadi target value (nilai yang akan diprediksi). Berikut adalah deskripsi dari data ini.
df.describe(include = 'all')#> name year ... torque seats
#> count 8128 8128.000000 ... 7906 7907.000000
#> unique 2058 NaN ... 441 NaN
#> top Maruti Swift Dzire VDI NaN ... 190Nm@ 2000rpm NaN
#> freq 129 NaN ... 530 NaN
#> mean NaN 2013.804011 ... NaN 5.416719
#> std NaN 4.044249 ... NaN 0.959588
#> min NaN 1983.000000 ... NaN 2.000000
#> 25% NaN 2011.000000 ... NaN 5.000000
#> 50% NaN 2015.000000 ... NaN 5.000000
#> 75% NaN 2017.000000 ... NaN 5.000000
#> max NaN 2020.000000 ... NaN 14.000000
#>
#> [11 rows x 13 columns]Kemudian perlu dilakukan pengecekan struktur data (tipe data) dan missing value pada dataset ini. Pengamatan terkait missing value dapat dilakukan secara visual dengan bantuan library missingno.
import missingno as msno
plt.figure()msno.matrix(df, figsize = (15,10))#> <AxesSubplot:>plt.show()
Berikut adalah informasi tekstual mengenai data yang hilang dan tipe data dari masing-masing kolom pada dataset ini.
df.info()#> <class 'pandas.core.frame.DataFrame'>
#> RangeIndex: 8128 entries, 0 to 8127
#> Data columns (total 13 columns):
#> # Column Non-Null Count Dtype
#> --- ------ -------------- -----
#> 0 name 8128 non-null object
#> 1 year 8128 non-null int64
#> 2 selling_price 8128 non-null int64
#> 3 km_driven 8128 non-null int64
#> 4 fuel 8128 non-null object
#> 5 seller_type 8128 non-null object
#> 6 transmission 8128 non-null object
#> 7 owner 8128 non-null object
#> 8 mileage 7907 non-null object
#> 9 engine 7907 non-null object
#> 10 max_power 7913 non-null object
#> 11 torque 7906 non-null object
#> 12 seats 7907 non-null float64
#> dtypes: float64(1), int64(3), object(9)
#> memory usage: 825.6+ KBData Preparation
Drop baris yang memiliki data yang hilang.
df.dropna(inplace = True)Pisahkan data numerik dan data kategorikal.
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
# Data numerik
df_num = df.select_dtypes(include=numerics)
# Data kategorikal
df_cat = df.drop(columns = df_num.columns, axis = 1)df_num.head()#> year selling_price km_driven seats
#> 0 2014 450000 145500 5.0
#> 1 2014 370000 120000 5.0
#> 2 2006 158000 140000 5.0
#> 3 2010 225000 127000 5.0
#> 4 2007 130000 120000 5.0df_cat.head()#> name fuel ... max_power torque
#> 0 Maruti Swift Dzire VDI Diesel ... 74 bhp 190Nm@ 2000rpm
#> 1 Skoda Rapid 1.5 TDI Ambition Diesel ... 103.52 bhp 250Nm@ 1500-2500rpm
#> 2 Honda City 2017-2020 EXi Petrol ... 78 bhp 12.7@ 2,700(kgm@ rpm)
#> 3 Hyundai i20 Sportz Diesel Diesel ... 90 bhp 22.4 kgm at 1750-2750rpm
#> 4 Maruti Swift VXI BSIII Petrol ... 88.2 bhp 11.5@ 4,500(kgm@ rpm)
#>
#> [5 rows x 9 columns]Pada data kategorikal, dapat dilihat bahwa beberapa kolom merupakan data yang dapat dijadikan numerik karena mengandung angka di dalamnya, yaitu data pada kolom mileage, engine, max_power, dan torque. Maka perlu dilakukan ekstraksi dengan bantuan regular expression untuk mengambil angka saja. Angka yang telah di ekstrak akan di format menjadi float atau integer dan dijadikan kolom baru pada dataframe numerik df_num.
df_num['mileage_kmpl'] = df_cat['mileage'].str.extract(r'([0-9.,]+)').astype('float')
df_num['engine_CC'] = df_cat['engine'].str.extract(r'([0-9.,]+)').astype('float')
df_num['max_power_bhp'] = df_cat['max_power'].str.extract(r'([0-9.,]+)').astype('float')Untuk kolom torque, dipisahkan menjadi 3 bagian, yaitu nilai Nm, rpm minimum, dan rpm maksimum. Apabila angka rpm hanya satu, rpm maksimum diasumsikan sama dengan rpm minimum.
df_cat['torque']#> 0 190Nm@ 2000rpm
#> 1 250Nm@ 1500-2500rpm
#> 2 12.7@ 2,700(kgm@ rpm)
#> 3 22.4 kgm at 1750-2750rpm
#> 4 11.5@ 4,500(kgm@ rpm)
#> ...
#> 8123 113.7Nm@ 4000rpm
#> 8124 24@ 1,900-2,750(kgm@ rpm)
#> 8125 190Nm@ 2000rpm
#> 8126 140Nm@ 1800-3000rpm
#> 8127 140Nm@ 1800-3000rpm
#> Name: torque, Length: 7906, dtype: objectdf_cat['torque'].str.extract(r'([.,0-9]+).*').head()#> 0
#> 0 190
#> 1 250
#> 2 12.7
#> 3 22.4
#> 4 11.5df_cat['torque'].str.extract(r'[0-9.,].+?[a-zA-Z@].+?([0-9.,]+)').replace(',','', regex=True).head()#> 0
#> 0 2000
#> 1 1500
#> 2 2700
#> 3 1750
#> 4 4500df_cat['torque'].str.extract(r'([\d,.]+)(?!.*\d)').replace(',','', regex=True).head()#> 0
#> 0 2000
#> 1 2500
#> 2 2700
#> 3 2750
#> 4 4500df_num['torque_Nm'] = df_cat['torque'].str.extract(r'([.,0-9]+).*').astype('float')
df_num['torque_rpm_min'] = df_cat['torque'].str.extract(r'[0-9.,].+?[a-zA-Z@].+?([0-9.,]+)').replace(',','', regex=True).astype('float')
df_num['torque_rpm_max'] = df_cat['torque'].str.extract(r'([\d,.]+)(?!.*\d)').replace(',','', regex=True).astype('float')df_num.head()#> year selling_price km_driven ... torque_Nm torque_rpm_min torque_rpm_max
#> 0 2014 450000 145500 ... 190.0 2000.0 2000.0
#> 1 2014 370000 120000 ... 250.0 1500.0 2500.0
#> 2 2006 158000 140000 ... 12.7 2700.0 2700.0
#> 3 2010 225000 127000 ... 22.4 1750.0 2750.0
#> 4 2007 130000 120000 ... 11.5 4500.0 4500.0
#>
#> [5 rows x 10 columns]Hapus kolom mileage, engine, max power, dan torque pada dataframe kategori karena kolom-kolom tersebut sudah menjadi bagian dari data numerikal.
df_cat.drop(columns = ['mileage', 'engine', 'max_power', 'torque'], axis = 1, inplace = True)df_cat.head()#> name fuel seller_type transmission owner
#> 0 Maruti Swift Dzire VDI Diesel Individual Manual First Owner
#> 1 Skoda Rapid 1.5 TDI Ambition Diesel Individual Manual Second Owner
#> 2 Honda City 2017-2020 EXi Petrol Individual Manual Third Owner
#> 3 Hyundai i20 Sportz Diesel Diesel Individual Manual First Owner
#> 4 Maruti Swift VXI BSIII Petrol Individual Manual First OwnerEDA and Feature Selection
Untuk menentukan fitur-fitur yang diperlukan pada data numerik, perlu dilihat korelasi fitur-fitur tersebut terhadap variabel selling_price selaku target value yang akan diprediksi.
plt.figure(figsize = (15,15))sns.heatmap(df_num.corr(), annot = True)#> <AxesSubplot:>plt.show()
plt.figure()sns.pairplot(df_num)
Pilih fitur-fitur yang memiliki korelasi tertinggi terhadap selling_price, pada kasus ini diambil fitur yang memiliki korelasi di atas 0.4. Fitur numerik dengan korelasi tertinggi dimuat di dalam variabel highest_corr_features.
plt.figure(figsize = (15,15))corr = df_num.corr()
# Ambil fitur dengan korelasi dengan selling_price di atas 0.4
highest_corr_features = corr.index[abs(corr["selling_price"])>0.4]
plt.figure(figsize=(10,10))g = sns.heatmap(df_num[highest_corr_features].corr(),annot=True,cmap="RdYlGn")
plt.show()
Untuk fitur data kategorikal, perlu dilihat terlebih dahulu berapa banyak unique value dari fitur tersebut.
df_cat.nunique()#> name 1982
#> fuel 4
#> seller_type 3
#> transmission 2
#> owner 5
#> dtype: int64Karena kolom name unique value nya sangat banyak, kolom name sebaiknya di drop karena sangat sedikit berpengaruh terhadap performa model. Selanjutnya akan dilakukan One-Hot Encoding (mengubah setiap kategori menjadi kolom) yang berisi nilai antara 0 atau 1.
# drop kolom name
df_cat.drop(columns = ['name'], axis = 1, inplace = True)# Lakukan One-Hot Encoding
df_cat = pd.get_dummies(df_cat)df_cat.head(3)#> fuel_CNG fuel_Diesel ... owner_Test Drive Car owner_Third Owner
#> 0 0 1 ... 0 0
#> 1 0 1 ... 0 0
#> 2 0 0 ... 0 1
#>
#> [3 rows x 14 columns]Selanjutnya akan dilakukan pemilihan fitur kategorikal. Fitur kategorikal dipilih berdasarkan nilai chi-squared terbesar. Semakin tinggi nilai chi squared maka semakin signifikan pengaruh fitur tersebut terhadap target value. Fitur kategorikal terbaik dimuat di dalam valiabel top_cat yang memuat 5 fitur terpenting.
# Selanjutnya memilih fitur kategorikal yang penting berdasarkan nilai chi2
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2# Applying kbest algo
ordered_rank_features = SelectKBest(score_func=chi2, k=14)
ordered_feature = ordered_rank_features.fit(df_cat,df_num['selling_price'])
ordered_feature.scores_#> array([ 926.72869219, 887.69415145, 1149.59778626, 1047.29106073,
#> 2733.56058706, 527.54944917, 2908.88674579, 3618.03100769,
#> 548.63368959, 663.81035178, 930.07841487, 917.43378246,
#> 4886.68063492, 978.79804926])df_scores = pd.DataFrame(ordered_feature.scores_, columns=['Score'])
df_columns = pd.DataFrame(df_cat.columns)
univariate_ranked = pd.concat([df_columns, df_scores],axis=1)
univariate_ranked.columns = ['Features', 'Scores']
univariate_ranked.set_index('Features', inplace = True)
# Ambil 5 fitur paling penting
top_cat = univariate_ranked.sort_values('Scores', ascending = False).head()
top_cat#> Scores
#> Features
#> owner_Test Drive Car 4886.680635
#> transmission_Automatic 3618.031008
#> seller_type_Trustmark Dealer 2908.886746
#> seller_type_Dealer 2733.560587
#> fuel_LPG 1149.597786Data kategorikal dan data numerikal disatukan kembali menjadi dataframe baru dengan nama df_new.
df_new = pd.concat([df_num, df_cat], axis = 1)df_new.head()#> year selling_price ... owner_Test Drive Car owner_Third Owner
#> 0 2014 450000 ... 0 0
#> 1 2014 370000 ... 0 0
#> 2 2006 158000 ... 0 1
#> 3 2010 225000 ... 0 0
#> 4 2007 130000 ... 0 0
#>
#> [5 rows x 24 columns]# cek kembali data yang hilang
df_new.isnull().sum()#> year 0
#> selling_price 0
#> km_driven 0
#> seats 0
#> mileage_kmpl 0
#> engine_CC 0
#> max_power_bhp 0
#> torque_Nm 0
#> torque_rpm_min 42
#> torque_rpm_max 0
#> fuel_CNG 0
#> fuel_Diesel 0
#> fuel_LPG 0
#> fuel_Petrol 0
#> seller_type_Dealer 0
#> seller_type_Individual 0
#> seller_type_Trustmark Dealer 0
#> transmission_Automatic 0
#> transmission_Manual 0
#> owner_First Owner 0
#> owner_Fourth & Above Owner 0
#> owner_Second Owner 0
#> owner_Test Drive Car 0
#> owner_Third Owner 0
#> dtype: int64# drop missing values
df_new.dropna(inplace = True)df_new.head()#> year selling_price ... owner_Test Drive Car owner_Third Owner
#> 0 2014 450000 ... 0 0
#> 1 2014 370000 ... 0 0
#> 2 2006 158000 ... 0 1
#> 3 2010 225000 ... 0 0
#> 4 2007 130000 ... 0 0
#>
#> [5 rows x 24 columns]Data Preprocessing
Pada tahap ini akan dilakukan preprocessing yaitu pemrosesan data awal yang bertujuan untuk mempersiapkan data agar dapat diterima oleh model machine learning dengan baik. Pada tahapan ini meliputi penentuan target value y, penentuan prediktor X, normalisasi data, dan train test split.
# Tentukan target value (y)
y = df_new['selling_price']# Menentukan predictor
# Fitur yang diambil untuk menjadi predictor adalah fitur yang telah melalui proses seleksi
# Highest corr features adalah fitur numerik dengan korelasi terhadap price yang tinggi
highest_corr_features.tolist()#> ['year', 'selling_price', 'engine_CC', 'max_power_bhp', 'torque_Nm']# top_cat adalah fitur kategori dengan nilai chi2 terhadap price yang tertinggi
top_cat.index.tolist()#> ['owner_Test Drive Car', 'transmission_Automatic', 'seller_type_Trustmark Dealer', 'seller_type_Dealer', 'fuel_LPG']# Tentukan predictor (X) dengan melakukan subsetting dataframe
X = df_new[top_cat.index.tolist()+highest_corr_features.tolist()]Setelah ditentukan target value dan predictor, dilanjutkan dengan normalisasi data menggunakan MinMaxScaler dan pembagian data train dan data test atau biasa dikenal dengan istilah train test split.
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score, mean_squared_error# Normalisasi data
sc = MinMaxScaler()
X = sc.fit_transform(X)# Train test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
X_train.shape, X_test.shape, y_train.shape, y_test.shape#> ((6291, 10), (1573, 10), (6291,), (1573,))Model Selection with GridSearchCV
GridSearchCV merupakan bagian dari modul scikit-learn yang bertujuan untuk melakukan validasi untuk lebih dari satu model dan hyperparameter masing-masing secara otomatis dan sistematis. Sebagai contoh, kita ingin mencoba model Decision Tree hyperparameter min_samples_leaf dengan nilai 1, 2, dan 3 dan min_samples_split dengan nilai 2,3, dan 4. GridSearchCV akan memilih hyperparameter mana yang akan memberikan model performa yang terbaik. Pada kasus ini, nilai cv diset 5 yang menandakan setiap kombinasi model dan parameter divalidasi sebanyak 5 kali dengan membagi data sebanyak 5 bagian sama besar secara acak (4 bagian untuk training dan 1 bagian untuk testing).
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor()
parameters = {
'min_samples_leaf': [1, 2, 3],
'min_samples_split': [2, 3, 4]
}search = GridSearchCV(model,
parameters,
cv = 5,
verbose=3)
search.fit(X, y)#> Fitting 5 folds for each of 9 candidates, totalling 45 fits
#> [CV 1/5] END min_samples_leaf=1, min_samples_split=2;, score=0.993 total time= 0.0s
#> [CV 2/5] END min_samples_leaf=1, min_samples_split=2;, score=0.999 total time= 0.0s
#> [CV 3/5] END min_samples_leaf=1, min_samples_split=2;, score=1.000 total time= 0.0s
#> [CV 4/5] END min_samples_leaf=1, min_samples_split=2;, score=1.000 total time= 0.0s
#> [CV 5/5] END min_samples_leaf=1, min_samples_split=2;, score=1.000 total time= 0.0s
#> [CV 1/5] END min_samples_leaf=1, min_samples_split=3;, score=0.992 total time= 0.0s
#> [CV 2/5] END min_samples_leaf=1, min_samples_split=3;, score=0.999 total time= 0.0s
#> [CV 3/5] END min_samples_leaf=1, min_samples_split=3;, score=1.000 total time= 0.0s
#> [CV 4/5] END min_samples_leaf=1, min_samples_split=3;, score=1.000 total time= 0.0s
#> [CV 5/5] END min_samples_leaf=1, min_samples_split=3;, score=1.000 total time= 0.0s
#> [CV 1/5] END min_samples_leaf=1, min_samples_split=4;, score=0.992 total time= 0.0s
#> [CV 2/5] END min_samples_leaf=1, min_samples_split=4;, score=0.999 total time= 0.0s
#> [CV 3/5] END min_samples_leaf=1, min_samples_split=4;, score=1.000 total time= 0.0s
#> [CV 4/5] END min_samples_leaf=1, min_samples_split=4;, score=1.000 total time= 0.0s
#> [CV 5/5] END min_samples_leaf=1, min_samples_split=4;, score=1.000 total time= 0.0s
#> [CV 1/5] END min_samples_leaf=2, min_samples_split=2;, score=0.992 total time= 0.0s
#> [CV 2/5] END min_samples_leaf=2, min_samples_split=2;, score=0.999 total time= 0.0s
#> [CV 3/5] END min_samples_leaf=2, min_samples_split=2;, score=1.000 total time= 0.0s
#> [CV 4/5] END min_samples_leaf=2, min_samples_split=2;, score=0.999 total time= 0.0s
#> [CV 5/5] END min_samples_leaf=2, min_samples_split=2;, score=1.000 total time= 0.0s
#> [CV 1/5] END min_samples_leaf=2, min_samples_split=3;, score=0.992 total time= 0.0s
#> [CV 2/5] END min_samples_leaf=2, min_samples_split=3;, score=0.999 total time= 0.0s
#> [CV 3/5] END min_samples_leaf=2, min_samples_split=3;, score=1.000 total time= 0.0s
#> [CV 4/5] END min_samples_leaf=2, min_samples_split=3;, score=0.999 total time= 0.0s
#> [CV 5/5] END min_samples_leaf=2, min_samples_split=3;, score=1.000 total time= 0.0s
#> [CV 1/5] END min_samples_leaf=2, min_samples_split=4;, score=0.992 total time= 0.0s
#> [CV 2/5] END min_samples_leaf=2, min_samples_split=4;, score=0.999 total time= 0.0s
#> [CV 3/5] END min_samples_leaf=2, min_samples_split=4;, score=1.000 total time= 0.0s
#> [CV 4/5] END min_samples_leaf=2, min_samples_split=4;, score=0.999 total time= 0.0s
#> [CV 5/5] END min_samples_leaf=2, min_samples_split=4;, score=1.000 total time= 0.0s
#> [CV 1/5] END min_samples_leaf=3, min_samples_split=2;, score=0.990 total time= 0.0s
#> [CV 2/5] END min_samples_leaf=3, min_samples_split=2;, score=1.000 total time= 0.0s
#> [CV 3/5] END min_samples_leaf=3, min_samples_split=2;, score=1.000 total time= 0.0s
#> [CV 4/5] END min_samples_leaf=3, min_samples_split=2;, score=0.999 total time= 0.0s
#> [CV 5/5] END min_samples_leaf=3, min_samples_split=2;, score=1.000 total time= 0.0s
#> [CV 1/5] END min_samples_leaf=3, min_samples_split=3;, score=0.990 total time= 0.0s
#> [CV 2/5] END min_samples_leaf=3, min_samples_split=3;, score=1.000 total time= 0.0s
#> [CV 3/5] END min_samples_leaf=3, min_samples_split=3;, score=1.000 total time= 0.0s
#> [CV 4/5] END min_samples_leaf=3, min_samples_split=3;, score=0.999 total time= 0.0s
#> [CV 5/5] END min_samples_leaf=3, min_samples_split=3;, score=1.000 total time= 0.0s
#> [CV 1/5] END min_samples_leaf=3, min_samples_split=4;, score=0.990 total time= 0.0s
#> [CV 2/5] END min_samples_leaf=3, min_samples_split=4;, score=1.000 total time= 0.0s
#> [CV 3/5] END min_samples_leaf=3, min_samples_split=4;, score=1.000 total time= 0.0s
#> [CV 4/5] END min_samples_leaf=3, min_samples_split=4;, score=0.999 total time= 0.0s
#> [CV 5/5] END min_samples_leaf=3, min_samples_split=4;, score=1.000 total time= 0.0s
#> GridSearchCV(cv=5, estimator=DecisionTreeRegressor(),
#> param_grid={'min_samples_leaf': [1, 2, 3],
#> 'min_samples_split': [2, 3, 4]},
#> verbose=3)Setelah dilakukan Grid Search, skor dan parameter terbaik dapat ditentukan seperti berikut ini.
search.best_score_, search.best_params_#> (0.9984489525832239, {'min_samples_leaf': 1, 'min_samples_split': 2})Parameter tersebut dapat langsung digunakan untuk melakukan prediksi terhadap selling_price.
model = DecisionTreeRegressor(min_samples_leaf = search.best_params_['min_samples_leaf'],
min_samples_split = search.best_params_['min_samples_split'])
model.fit(X_train, y_train)#> DecisionTreeRegressor()y_pred = model.predict(X_test)
print('r-squared is ', r2_score(y_test, y_pred),' and root_mean_squared_error is ', mean_squared_error(y_test, y_pred, squared = False))#> r-squared is 0.9998793137480012 and root_mean_squared_error is 8295.357724466106def plot_result(prediction, actual):
plt.figure(figsize = (7,7))
plt.scatter(prediction, actual, color = 'r', s = 5)
plt.xlabel('Prediction')
plt.ylabel('Actual')
plt.plot([0,3e6], [0,3e6])
plt.show()
plot_result(y_pred, y_test)
Apabila ingin mencoba lebih dari satu buah model, grid search dilakukan dengan melakukan iterasi untuk setiap model. Karena setiap model memiliki input parameter yang berbeda-beda, iterasi harus berjalan untuk setiap model sesuai dengan parameternya masing-masing. Untuk menangani hal tersebut, perlu dirancang kumpulan dictionary sebagai berikut ini. Asumsikan kita ingin mencoba mode Linear Regression, Decision Tree Regressor, dan Random Forest Regressor dengan masing-masing parameter seperti tertera di bawah ini.
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
model_params = {
'linear_regression': {
'model': LinearRegression(),
'params' : {
# No Parameter
}
},
'decision_tree': {
'model': DecisionTreeRegressor(),
'params' : {
'min_samples_leaf' : [1,2,3]
}
},
'random_forest': {
'model': RandomForestRegressor(),
'params' : {
'n_estimators': [100, 500],
'min_samples_leaf' : [1,2,3]
}
},
}GridSearchCV dilakukan dengan iterasi untuk setiap model. Skor dan parameter terbaik disimpan di dalam list scores yang nantinya akan dimuat dalam bentuk dataframe.
scores = []
for model_name, mp in model_params.items():
clf = GridSearchCV(mp['model'], mp['params'], cv=5, return_train_score=False)
clf.fit(X, y)
scores.append({
'model': model_name,
'best_score': clf.best_score_,
'best_params': clf.best_params_
})
#> GridSearchCV(cv=5, estimator=LinearRegression(), param_grid={})
#> GridSearchCV(cv=5, estimator=DecisionTreeRegressor(),
#> param_grid={'min_samples_leaf': [1, 2, 3]})
#> GridSearchCV(cv=5, estimator=RandomForestRegressor(),
#> param_grid={'min_samples_leaf': [1, 2, 3],
#> 'n_estimators': [100, 500]})score_df = pd.DataFrame(scores,columns=['model','best_score','best_params'])
score_df#> model best_score best_params
#> 0 linear_regression 1.000000 {}
#> 1 decision_tree 0.997913 {'min_samples_leaf': 2}
#> 2 random_forest 0.997849 {'min_samples_leaf': 1, 'n_estimators': 500}Dapat dilihat bahwa model Simple Linear Regression memiliki r-squared score tertinggi. Sehingga model ini dapat langsung digunakan untuk memprediksi target value.
model = LinearRegression()
model.fit(X_train, y_train)#> LinearRegression()y_pred = model.predict(X_test)
print('r-squared is ', r2_score(y_test, y_pred),' and root_mean_squared_error is ', mean_squared_error(y_test, y_pred, squared = False))#> r-squared is 1.0 and root_mean_squared_error is 1.3150676180075858e-09plot_result(y_pred, y_test)
Conclusion
Penentuan hasil prediksi dari suatu data dititikberatkan pada pemilihan model dan parameter yang baik. Grid Search Cross Validation mempermudah kita dalam menguji coba setiap model dan parameter model machine learning tanpa harus mencoba melakukan validasi secara manual satu persatu. Penerapan Grid Search Cross Validation yang disandingkan dengan pemahaman dan intuisi yang baik terkait model machine learning dan data yang digunakan akan memberikan hasil prediksi yang akurat dan optimal.
Dokumentasi GridSearchCV library sklearn
Cross Validation and Grid Search for Model Selection in Python
 More details
More details More details
More details
Share this post
Twitter
Facebook
LinkedIn